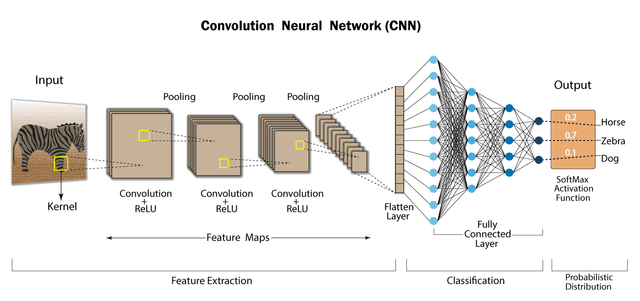
CNN
# Tag:
- Source/SUNI_CCTV
- Source/KU_ML2
- Subject/AI/Vision
toc test
CNN (Convolutional Neural Network)
이미지를 특정한 영역 별로 추출하여 학습시키는 방식의 ANN. 추출한 데이터를 kernel과 convolution 연산을 통해 특징적인 값을 찾아내어 학습한다.
기존의 ANN이 단순히 일렬로 늘어놓은 vector에 대해 Linear한 연산을 수행하는 것이었다면, CNN은 이미지의 지역적 특성을 반영해 convolution 형태의 linear 연산을 수행하는 것이라 할 수 있다.
- Adjacency: 이미지 데이터는 local한 부분의 pattern이 의미를 지니므로 이를 활용해야 한다.
- 즉, 고양이의 사진이라면 그 중 귀(ear)는 그 local한 pattern을 그대로 활용해야 제대로 학습할 수 있다.
- 이를 반영하기 위해, kernel에 대하여 2차원의 local한 pattern에 대해 convolution하는 방식을 이용한다.
- Spatial invariance: 다른 공간에 위치해도 혼동하지 않아야 한다.
- 예를 들어, 눈(eye)와 귀(ear)의 위치를 바꾼 사진을 fully-connect 방식의 넣는다면 똑같이 인식하므로, 그 위치의 특성을 이해하지 못한다.
- Number of Weights: 기존의 단순히 이미지를 vector로 만들어 Weight와 inner product하는 linear 연산은, 너무 큰 차원의 weights를 가지게 된다.
보통 이미지는 의 2차원의 이미지에, RGB 혹은 다른 표현 방식으로 channel(depth)를 가지게 되어 보통 Tensor로 표현된다.
이에 대해 각각의 2차원 이미지 patch에 대해 kernel을 이용해 colvolution을 적용하고, 똑같은 위치의 다른 channel 이미지에도 적용해 하나의 값으로 더한다. 일종의 linear operation이다.
kernel은 weights로 구성된 일종의 linear function이다.
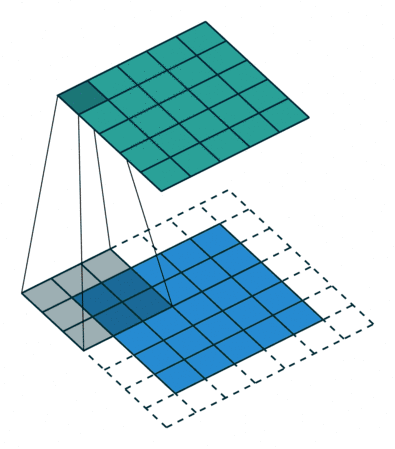
Convolution
어떠한 filter에 대하여, 그 크기에 해당하는 이미지 patch의 각 픽셀에 대해 그 filter(kernel)를 곱하고 모두 더하여 feature map을 만드는 과정.
kernel은 여러 개를 사용할 수도 있으며, 이는 새롭게 만들어지는 feature map이 kernel의 개수만큼 channel을 가지게 된다.
이러한 Kernel을 한 칸씩 오른쪽으로, 그리고 아래쪽으로 이동해가며 적용하는데 이 때 kernel의 weight를 공유하게 된다.
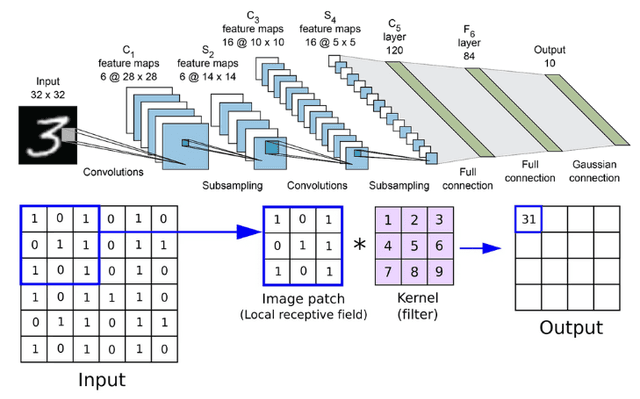
이미지의 Patch를 자르는 것은, 각 이미지의 부분(Patch)의 특징을 추출해내어, 신경망이 학습하도록 하기 위함이다.
- Zero-Padding: 이미지 테두리에 0(검정)을 배치하여, 테두리 부분을 키워, Activaiton Map의 크기를 유지하도록 할 수도 있다.
- Stride: kernel을 이미지에 대해 오른쪽으로 한 칸씩, 아래쪽으로 한 칸씩 이동해가며 convlution을 적용해가는 것은 Stride = 1이라 할 수 있다.
- 여러 칸을 이동하게 된다면, Stride는 1 이상으로, 이동할 간격을 의미한다.
- Pooling: Convolution을 적용하고 난 후에, 비슷한 pattern에 대해 down sampling을 진행하는 방식이다.
- mini-batch: 이미지를 N개씩 훈련하도록 하여, 훈련 효율성을 높인다.
- one-batch: 메모리 할당이 적지만, 데이터 전체의 경향을 담지 못한다.
- full-batch: 메모리 할당이 많지만, 데이터 전체의 경향을 담을 수 있다.